Many of the ethical issues that face IT professionals involve privacy. For example:
Should you read the private e-mail of your network users just “because you can?” Is it okay to read employees’ e-mail as a security measure, to ensure that sensitive company information isn’t being disclosed? Is it okay to read employees’ e-mail to ensure that company rules (for instance, against personal use of the e-mail system) aren’t being violated? If you do read employees’ e-mail, should you disclose that policy to them? Before or after the fact?
Is it okay to monitor the Web sites visited by your network users? Should you routinely keep logs of visited sites? Is it negligent to not monitor such Internet usage, to prevent the possibility of pornography in the workplace that could create a hostile work environment?
Is it okay to place key loggers on machines on the network to capture everything the user types? Screen capture programs so you can see everything that’s displayed? Should users be informed that they’re being watched in this way?
Is it okay to read the documents and look at the graphics files that are stored on users’ computers or in their directories on the file server?
Remember that we’re not talking about legal questions here. A company may very well have the legal right to monitor everything an employee does with its computer equipment. We’re talking about the ethical aspects of having the ability to do so.
As a network administrator or security professional, you have rights and privileges that allow you to access most of the data on the systems on your network. You may even be able to access encrypted data if you have access to the recovery agent account. What you do with those abilities depend in part on your particular job duties (for example, if monitoring employee mail is a part of your official job description) and in part on your personal ethical beliefs about these issues.
The slippery slope
A common concept in any ethics discussion is the “slippery slope.” This pertains to the ease with which a person can go from doing something that doesn’t really seem unethical (such as scanning employees’ e-mail “just for fun”) to doing things that are increasingly unethical (such as making little changes in their mail messages or diverting messages to the wrong recipient).
In looking at the list of privacy issues above, it’s easy to justify each of the actions described. But it’s also easy to see how each of those actions could “morph” into much less justifiable actions. For example, the information you gained from reading someone’s e-mail could be used to embarrass that person, to gain a political advantage within the company, to get him/her disciplined or fired, or even for blackmail.
The slippery slope concept can also go beyond using your IT skills. If it’s okay to read other employees’ e-mail, is it also okay to go through their desk drawers when they aren’t there? To open their briefcases or purses?
Real world ethical dilemmas
What if your perusal of random documents reveals company trade secrets? What if you later leave the company and go to work for a competitor? Is it wrong to use that knowledge in your new job? Would it be “more wrong” if you printed out those documents and took them with you, than if you just relied on your memory?
What if the documents you read showed that the company was violating government regulations or laws? Do you have a moral obligation to turn them in, or are you ethically bound to respect your employer’s privacy? Would it make a difference if you signed a non-disclosure agreement when you accepted the job?
IT and security consultants who do work for multiple companies have even more ethical issues to deal with. If you learn things about one of your clients that might affect your other client(s), where does your loyalty lie?
Then there are money issues. The proliferation of network attacks, hacks, viruses, and other threats to their IT infrastructures have caused many companies to “be afraid, be very afraid.” As a security consultant, it may be very easy to play on that fear to convince companies to spend far more money than they really need to. Is it wrong for you to charge hundreds or even thousands of dollars per hour for your services, or is it a case of “whatever the market will bear?” Is it wrong for you to mark up the equipment and software that you get for the customer when you pass the cost through? What about kickbacks from equipment manufacturers? Is it wrong to accept “commissions” from them for convincing your clients to go with their products? Or what if the connection is more subtle? Is it wrong to steer your clients toward the products of companies in which you hold stock?
Another ethical issue involves promising more than you can deliver, or manipulating data to obtain higher fees. You can install technologies and configure settings to make a client’s network more secure, but you can never make it completely secure. Is it wrong to talk a client into replacing their current firewalls with those of a different manufacturer, or switching to an open source operating system – which changes, coincidentally, will result in many more billable hours for you – on the premise that this is the answer to their security problems?
think about it.........
Is it a satisfaction to hack and know about other people information?
if this case regarding to competitive competition?..you cheated man!!!
Network security consists of the provisions and policies adopted by a network administrator to prevent and monitor unauthorized access, misuse, modification, or denial of a computer network and network-accessible resources. Network security involves the authorization of access to data in a network, which is controlled by the network administrator. Users choose or are assigned an ID and password or other authenticating information that allows them access to information and programs within their authority. Network security covers a variety of computer networks, both public and private, that are used in everyday jobs conducting transactions and communications among businesses, government agencies and individuals. Networks can be private, such as within a company, and others which might be open to public access. Network security is involved in organizations, enterprises, and other types of institutions. It does as its title explains: It secures the network, as well as protecting and overseeing operations being done. The most common and simple way of protecting a network resource is by assigning it a unique name and a corresponding password.
Network security starts with authenticating the user, commonly with a username and a password. Since this requires just one detail authenticating the user name —i.e. the password, which is something the user 'knows'— this is sometimes termed one-factor authentication. With two-factor authentication, something the user 'has' is also used (e.g. a security token or 'dongle', an ATM card, or a mobile phone); and with three-factor authentication, something the user 'is' is also used (e.g. a fingerprint or retinal scan).
Once authenticated, a firewall enforces access policies such as what services are allowed to be accessed by the network users. Though effective to prevent unauthorized access, this component may fail to check potentially harmful content such as computer worms or Trojans being transmitted over the network. Anti-virus software or an intrusion prevention system (IPS) help detect and inhibit the action of such malware. An anomaly-based intrusion detection system may also monitor the network and traffic for unexpected (i.e. suspicious) content or behavior and other anomalies to protect resources, e.g. from denial of service attacks or an employee accessing files at strange times. Individual events occurring on the network may be logged for audit purposes and for later high-level analysis.
Communication between two hosts using a network may be encrypted to maintain privacy.
Honeypots, essentially decoy network-accessible resources, may be deployed in a network as surveillance and early-warning tools, as the honeypots are not normally accessed for legitimate purposes. Techniques used by the attackers that attempt to compromise these decoy resources are studied during and after an attack to keep an eye on new exploitation techniques. Such analysis may be used to further tighten security of the actual network being protected by the honeypot.
Security management
Security management for networks is different for all kinds of situations. A home or small office may only require basic security while large businesses may require high-maintenance and advanced software and hardware to prevent malicious attacks from hacking and spamming.
Web conferencing refers to a service that allows conferencing events to be shared with remote locations. In general the service is made possible by Internet technologies, particularly on TCP/IP connections. The service allows real-time point-to-point communications as well as multicast communications from one sender to many receivers. It offers information of text-based messages, voice and video chat to be shared simultaneously, across geographically dispersed locations. Applications for web conferencing include meetings, training events, lectures, or short presentations from any computer.
Some web conferencing solutions require additional software to be installed (usually via download) by the presenter and participants, while others eliminate this step by providing physical hardware or an appliance. In general, system requirements depend on the vendor. Some web conferencing services vendors provide a complete solution while others enhance existing technologies. Most also provide a means of interfacing with email and calendaring clients in order that customers can plan an event and share information about it, in advance. A participant can be either an individual person or a group. System requirements that allow individuals within a group to participate as individuals (e.g. when an audience participant asks a question) depend on the size of the group. Handling such requirements is often the responsibility of the group. Most vendors also provide either a recorded copy of an event, or a means for a subscriber to record an event. Support for planning a shared event is typically integrated with calendar and email applications. The method of controlling access to an event is provided by the vendor. Additional value-added features are included as desired by vendors who provide them. Besides exceptions (e.g. Openmeetings, TokBox, WebHuddle, BigBlueButton), web conferencing services do not apply free software but proprietary software, see Comparison of web conferencing software.
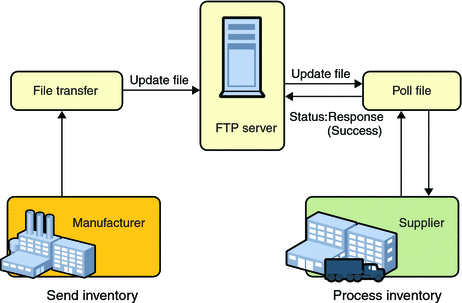
File Transfer Protocol (FTP) is a standard network protocol used to transfer files from one host to another host over a TCP-based network, such as the Internet. It is often used to upload web pages and other documents from a private development machine to a public web-hosting server. FTP is built on a client-server architecture and uses separate control and data connections between the client and the server. FTP users may authenticate themselves using a clear-text sign-in protocol, normally in the form of a username and password, but can connect anonymously if the server is configured to allow it. For secure transmission that hides (encrypts) your username and password, as well as encrypts the content, you can try using a client that uses SSH File Transfer Protocol.
The first FTP client applications were interactive command-line tools, implementing standard commands and syntax. Graphical user interfaces have since been developed for many of the popular desktop operating systems in use today, including general web design programs like Microsoft Expression Web, and specialist FTP clients such as CuteFTP.
Communication and data transfer
The protocol is specified in RFC 959, which is summarized here.
The server responds over the control connection with three-digit status codes in ASCII with an optional text message. For example "200" (or "200 OK") means that the last command was successful. The numbers represent the code for the response and the optional text represents a human-readable explanation or request (e.g. <Need account for storing file>).An ongoing transfer of file data over the data connection can be aborted using an interrupt message sent over the control connection.
Illustration of starting a passive connection using port 21
FTP may run in active or passive mode, which determines how the data connection is established. In active mode, the client creates a TCP control connection to the server and sends the server the client's IP address and an arbitrary client port number, and then waits until the server initiates the data connection over TCP to that client IP address and client port number. In situations where the client is behind a firewall and unable to accept incoming TCP connections, passive mode may be used. In this mode, the client uses the control connection to send a PASV command to the server and then receives a server IP address and server port number from the server,which the client then uses to open a data connection from an arbitrary client port to the server IP address and server port number received. Both modes were updated in September 1998 to support IPv6. Further changes were introduced to the passive mode at that time, updating it to extended passive mode.
While transferring data over the network, four data representations can be used:
ASCII mode: used for text. Data is converted, if needed, from the sending host's character representation to "8-bit ASCII" before transmission, and (again, if necessary) to the receiving host's character representation. As a consequence, this mode is inappropriate for files that contain data other than plain text.
Image mode (commonly called Binary mode): the sending machine sends each file byte for byte, and the recipient stores the bytestream as it receives it. (Image mode support has been recommended for all implementations of FTP).
EBCDIC mode: use for plain text between hosts using the EBCDIC character set. This mode is otherwise like ASCII mode.
Local mode: Allows two computers with identical setups to send data in a proprietary format without the need to convert it to ASCII
For text files, different format control and record structure options are provided. These features were designed to facilitate files containing Telnet or ASA formatting.
Data transfer can be done in any of three modes:
Stream mode: Data is sent as a continuous stream, relieving FTP from doing any processing. Rather, all processing is left up to TCP. No End-of-file indicator is needed, unless the data is divided into records.
Block mode: FTP breaks the data into several blocks (block header, byte count, and data field) and then passes it on to TCP.
Compressed mode: Data is compressed using a single algorithm (usually run-length encoding).
[edit]Login
FTP login utilizes a normal usernames and password scheme for granting access. The username is sent to the server using the USER command, and the password is sent using the PASS command.[ If the information provided by the client is accepted by the server, the server will send a greeting to the client and the session will commence. If the server supports it, users may log in without providing login credentials, but the server may authorize only limited access for such sessions.
[edit]Anonymous FTP
A host that provides an FTP service may provide anonymous FTP access. Users typically log into the service with an 'anonymous' (lower-case and case-sensitive in some FTP servers) account when prompted for user name. Although users are commonly asked to send their email address in lieu of a password, no verification is actually performed on the supplied data. Many FTP hosts whose purpose is to provide software updates will provide anonymous logins.
NAT and firewall traversal
FTP normally transfers data by having the server connect back to the client, after the PORT command is sent by the client. This is problematic for both NATs and firewalls, which do not allow connections from the Internet towards internal hosts.For NATs, an additional complication is that the representation of the IP addresses and port number in the PORT command refer to the internal host's IP address and port, rather than the public IP address and port of the NAT.
There are two approaches to this problem. One is that the FTP client and FTP server use the PASV command, which causes the data connection to be established from the FTP client to the server. This is widely used by modern FTP clients. Another approach is for the NAT to alter the values of the PORT command, using an application-level gateway for this purpose.
[edit]Web browser support
Most common web browsers can retrieve files hosted on FTP servers, although they may not support protocol extensions such as FTPS.[3][12] When an FTP—rather than an HTTP—URL is supplied, the accessible contents on the remote server are presented in a manner that is similar to that used for other Web content. A full-featured FTP client can be run within Firefox in the form of an extension called FireFTP
[edit]Syntax
FTP URL syntax is described in RFC1738,[13] taking the form: ftp://[<user>[:<password>]@]<host>[:<port>]/<url-path>[13] (The bracketed parts are optional.) For example:
ftp://public.ftp-servers.example.com/mydirectory/myfile.txt
or:
ftp://user001:secretpassword@private.ftp-servers.example.com/mydirectory/myfile.txt
More details on specifying a username and password may be found in the browsers' documentation, such as, for example, Firefox and Internet Explorer. By default, most web browsers use passive (PASV) mode, which more easily traverses end-user firewalls.
Security
FTP was not designed to be a secure protocol—especially by today's standards—and has many security weaknesses. In May 1999, the authors of RFC 2577 listed a vulnerability to the following problems:
Bounce attacks
Spoof attacks
Brute force attacks
Packet capture (sniffing)
Username protection
Port stealing
FTP is not able to encrypt its traffic; all transmissions are in clear text, and usernames, passwords, commands and data can be easily read by anyone able to perform packet capture (sniffing) on the network. This problem is common to many of the Internet Protocol specifications (such as SMTP, Telnet, POP and IMAP) that were designed prior to the creation of encryption mechanisms such as TLS or SSL. A common solution to this problem is to use the "secure", TLS-protected versions of the insecure protocols (e.g. FTPS for FTP, TelnetS for Telnet, etc.) or a different, more secure protocol that can handle the job, such as the SFTP/SCP tools included with most implementations of the Secure Shell protocol.
Secure FTP
There are several methods of securely transferring files that have been called "Secure FTP" at one point or another.
FTPS
Explicit FTPS is an extension to the FTP standard that allows clients to request that the FTP session be encrypted. This is done by sending the "AUTH TLS" command. The server has the option of allowing or denying connections that do not request TLS. This protocol extension is defined in the proposed standard: RFC 4217. Implicit FTPS is a deprecated standard for FTP that required the use of a SSL or TLS connection. It was specified to use different ports than plain FTP.
SFTP
SFTP, the "SSH File Transfer Protocol," is not related to FTP except that it also transfers files and has a similar command set for users. SFTP, or secure FTP, is a program that uses Secure Shell (SSH) to transfer files. Unlike standard FTP, it encrypts both commands and data, preventing passwords and sensitive information from being transmitted openly over the network. It is functionally similar to FTP, but because it uses a different protocol, you can't use a standard FTP client to talk to an SFTP server, nor can you connect to an FTP server with a client that supports only SFTP.
FTP over SSH (not SFTP)
FTP over SSH (not SFTP) refers to the practice of tunneling a normal FTP session over an SSH connection. Because FTP uses multiple TCP connections (unusual for a TCP/IP protocol that is still in use), it is particularly difficult to tunnel over SSH. With many SSH clients, attempting to set up a tunnel for the control channel (the initial client-to-server connection on port 21) will protect only that channel; when data is transferred, the FTP software at either end will set up new TCP connections (data channels), which bypass the SSH connection and thus have no confidentiality or integrity protection, etc.
Otherwise, it is necessary for the SSH client software to have specific knowledge of the FTP protocol, to monitor and rewrite FTP control channel messages and autonomously open new packet forwardings for FTP data channels. Software packages that support this mode are:
Tectia ConnectSecure (Win/Linux/Unix) of SSH Communications Security's software suite
Tectia Server for IBM z/OS of SSH Communications Security's software suite
FONC (the GPL licensed)
Co:Z FTPSSH Proxy
FTP over SSH is sometimes referred to as secure FTP; this should not be confused with other methods of securing FTP, such as SSL/TLS (FTPS). Other methods of transferring files using SSH that are not related to FTP include SFTP and SCP; in each of these, the entire conversation (credentials and data) is always protected by the SSH protocol.
HTML is not a programming language, it is a mark-up language
A mark-up language is a set of markup tags
HTML uses mark-up tags to describe web pages
HTML is written in the form of HTML elements consisting of tags enclosed in angle brackets (like <html>), within the web page content. HTML tags most commonly come in pairs like <h1> and </h1>, although some tags, known as empty elements, are unpaired, for example <img>. The first tag in a pair is the start tag, the second tag is the end tag (they are also called opening tags and closing tags). In between these tags web designers can add text, tags, comments and other types of text-based content.
The purpose of a web browser is to read HTML documents and compose them into visible or audible web pages. The browser does not display the HTML tags, but uses the tags to interpret the content of the page.
HTML elements form the building blocks of all websites. HTML allows images and objects to be embedded and can be used to create interactive forms. It provides a means to create structured documents by denoting structural semantics for text such as headings, paragraphs, lists, links, quotes and other items. It can embed scripts in languages such as JavaScript which affect the behavior of HTML webpages.
During that class, we had learned how to build our own webpage...
It was fun to learn although we just had learned the most basic steps in learning html.
thank you so much MR. RAZAK, now we can create and design our webpage easily.....
A web search engine is designed to search for information on the World Wide Web. The search results are generally presented in a list of results often referred to as search engine results pages (SERPs). The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. Unlike web directories, which are maintained only by human editors, search engines also maintain real-time information by running an algorithm on a web crawler.
A search engine operates in the following order:
Web crawling
Indexing
Searching
Web search engines work by storing information about many web pages, which they retrieve from the HTML itself. These pages are retrieved by a Web crawler (sometimes also known as a spider) — an automated Web browser which follows every link on the site. Exclusions can be made by the use of robots.txt. The contents of each page are then analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called meta tags). Data about web pages are stored in an index database for use in later queries. A query can be a single word. The purpose of an index is to allow information to be found as quickly as possible. Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages, whereas others, such as AltaVista, store every word of every page they find. This cached page always holds the actual search text since it is the one that was actually indexed, so it can be very useful when the content of the current page has been updated and the search terms are no longer in it. This problem might be considered to be a mild form of linkrot, and Google's handling of it increases usability by satisfying user expectations that the search terms will be on the returned webpage. This satisfies the principle of least astonishment since the user normally expects the search terms to be on the returned pages. Increased search relevance makes these cached pages very useful, even beyond the fact that they may contain data that may no longer be available elsewhere.
When a user enters a query into a search engine (typically by using keywords), the engine examines its index and provides a listing of best-matching web pages according to its criteria, usually with a short summary containing the document's title and sometimes parts of the text. The index is built from the information stored with the data and the method by which the information is indexed. Unfortunately, there are currently no known public search engines that allow documents to be searched by date. Most search engines support the use of the boolean operators AND, OR and NOT to further specify the search query. Boolean operators are for literal searches that allow the user to refine and extend the terms of the search. The engine looks for the words or phrases exactly as entered. Some search engines provide an advanced feature called proximity search which allows users to define the distance between keywords. There is also concept-based searching where the research involves using statistical analysis on pages containing the words or phrases you search for. As well, natural language queries allow the user to type a question in the same form one would ask it to a human. A site like this would be ask.com.
The usefulness of a search engine depends on the relevance of the result set it gives back. While there may be millions of web pages that include a particular word or phrase, some pages may be more relevant, popular, or authoritative than others. Most search engines employ methods to rank the results to provide the "best" results first. How a search engine decides which pages are the best matches, and what order the results should be shown in, varies widely from one engine to another. The methods also change over time as Internet usage changes and new techniques evolve. There are two main types of search engine that have evolved: one is a system of predefined and hierarchically ordered keywords that humans have programmed extensively. The other is a system that generates an "inverted index" by analyzing texts it locates. This second form relies much more heavily on the computer itself to do the bulk of the work.
Most Web search engines are commercial ventures supported by advertising revenue and, as a result, some employ the practice of allowing advertisers to pay money to have their listings ranked higher in search results. Those search engines which do not accept money for their search engine results make money by running search related ads alongside the regular search engine results. The search engines make money every time someone clicks on one of these ads.
MR. WIKI...SARANGHAEYO~~~~
Web 2.0
- is a loosely defined intersection of web application features that facilitate participatory information sharing, interoperability, user-centered design, and collaboration on the World Wide Web. A Web 2.0 site allows users to interact and collaborate with each other in a social media dialogue as creators (prosumers) of user-generated content in a virtual community, in contrast to websites where users (consumers) are limited to the passive viewing of content that was created for them. Examples of Web 2.0 include social networking sites, blogs, wikis, video sharing sites, hosted services, web applications, mashups and folksonomies.
CHARACTERISTICS
Web 2.0 websites allow users to do more than just retrieve information. By increasing what was already possible in "Web 1.0", they provide the user with more user-interface, software and storage facilities, all through their browser. This has been called "Network as platform" computing. Users can provide the data that is on a Web 2.0 site and exercise some control over that data. These sites may have an "Architecture of participation" that encourages users to add value to the application as they use it. Some scholars have made the case that cloud computing is a form of Web 2.0 because cloud computing is simply an implication of computing on the Internet.
The concept of Web-as-participation-platform captures many of these characteristics. Bart Decrem, a founder and former CEO of Flock, calls Web 2.0 the "participatory Web" and regards the Web-as-information-source as Web 1.0.
The Web 2.0 offers all users the same freedom to contribute. While this opens the possibility for rational debate and collaboration, it also opens the possibility for "spamming" and "trolling" by less rational users. The impossibility of excluding group members who don’t contribute to the provision of goods from sharing profits gives rise to the possibility that rational members will prefer to withhold their contribution of effort and free ride on the contribution of others. This requires what is sometimes called radical trust by the management of the website. According to Best, the characteristics of Web 2.0 are: rich user experience, user participation, dynamic content, metadata, web standards and scalability. Further characteristics, such as openness, freedom and collective intelligence by way of user participation, can also be viewed as essential attributes of Web 2.0.
TECHNOLOGIES
A third important part of Web 2.0 is the social Web, which is a fundamental shift in the way people communicate. The social web consists of a number of online tools and platforms where people share their perspectives, opinions, thoughts and experiences. Web 2.0 applications tend to interact much more with the end user. As such, the end user is not only a user of the application but also a participant by:
Podcasting
Blogging
Tagging
Contributing to RSS
Social bookmarking
Social networking
The popularity of the term Web 2.0, along with the increasing use of blogs, wikis, and social networking technologies, has led many in academia and business to coin a flurry of 2.0s, including Library 2.0,Social Work 2.0, Enterprise 2.0, PR 2.0, Classroom 2.0, Publishing 2.0, Medicine 2.0, Telco 2.0, Travel 2.0, Government 2.0, and even Porn 2.0. Many of these 2.0s refer to Web 2.0 technologies as the source of the new version in their respective disciplines and areas. For example, in the Talis white paper "Library 2.0: The Challenge of Disruptive Innovation", Paul Miller argues
Blogs, wikis and RSS are often held up as exemplary manifestations of Web 2.0. A reader of a blog or a wiki is provided with tools to add a comment or even, in the case of the wiki, to edit the content. This is what we call the Read/Write web. Talis believes that Library 2.0 means harnessing this type of participation so that libraries can benefit from increasingly rich collaborative cataloging efforts, such as including contributions from partner libraries as well as adding rich enhancements, such as book jackets or movie files, to records from publishers and others.
Here, Miller links Web 2.0 technologies and the culture of participation that they engender to the field of library science, supporting his claim that there is now a "Library 2.0". Many of the other proponents of new 2.0s mentioned here use similar methods.
The meaning of web 2.0 is role dependent, as Dennis D. McDonalds noted. For example, some use Web 2.0 to establish and maintain relationships through social networks, while some marketing managers might use this promising technology to "end-run traditionally unresponsive I.T. department[s]."
There is a debate over the use of Web 2.0 technologies in mainstream education. Issues under consideration include the understanding of students' different learning modes; the conflicts between ideas entrenched in informal on-line communities and educational establishments' views on the production and authentication of 'formal' knowledge; and questions about privacy, plagiarism, shared authorship and the ownership of knowledge and information produced and/or published on line.
Marketing
For marketers, Web 2.0 offers an opportunity to engage consumers. A growing number of marketers are using Web 2.0 tools to collaborate with consumers on product development, service enhancement and promotion. Companies can use Web 2.0 tools to improve collaboration with both its business partners and consumers. Among other things, company employees have created wikis—Web sites that allow users to add, delete, and edit content — to list answers to frequently asked questions about each product, and consumers have added significant contributions. Another marketing Web 2.0 lure is to make sure consumers can use the online community to network among themselves on topics of their own choosing.
Mainstream media usage of web 2.0 is increasing. Saturating media hubs—like The New York Times, PC Magazine and Business Week — with links to popular new web sites and services, is critical to achieving the threshold for mass adoption of those services.
Web 2.0 offers financial institutions abundant opportunities to engage with customers. Networks such as Twitter, Yelp and Facebook are now becoming common elements of multichannel and customer loyalty strategies, and banks are beginning to use these sites proactively to spread their messages. In a recent article for Bank Technology News, Shane Kite describes how Citigroup's Global Transaction Services unit monitors social media outlets to address customer issues and improve products. Furthermore, the FI uses Twitter to release "breaking news" and upcoming events, and YouTube to disseminate videos that feature executives speaking about market news.
Small businesses have become more competitive by using Web 2.0 marketing strategies to compete with larger companies. As new businesses grow and develop, new technology is used to decrease the gap between businesses and customers. Social networks have become more intuitive and user friendly to provide information that is easily reached by the end user. For example, companies use Twitter to offer customers coupons and discounts for products and services.
According to Google Timeline, the term Web 2.0 was discussed and indexed most frequently in 2005, 2007 and 2008. Its average use is continuously declining by 2–4% per quarter since April 2008.
for more application..you can click on this link!!
EMAIL
Electronic mail, commonly known as email or e-mail, is a method of exchanging digital messages from an author to one or more recipients. Modern email operates across the Internet or other computer networks. Some early email systems required that the author and the recipient both be online at the same time, in common with instant messaging. Today's email systems are based on a store-and-forward model. Email servers accept, forward, deliver and store messages. Neither the users nor their computers are required to be online simultaneously; they need connect only briefly, typically to an email server, for as long as it takes to send or receive messages.
An email message consists of three components, the message envelope, the message header, and the message body. The message header contains control information, including, minimally, an originator's email address and one or more recipient addresses. Usually descriptive information is also added, such as a subject header field and a message submission date/time stamp.
Originally a text-only (7-bit ASCII and others) communications medium, email was extended to carry multi-media content attachments, a process standardized in RFC 2045 through 2049. Collectively, these RFCs have come to be called Multipurpose Internet Mail Extensions (MIME).
Electronic mail predates the inception of the Internet, and was in fact a crucial tool in creating it,[2] but the history of modern, global Internet email services reaches back to the early ARPANET. Standards for encoding email messages were proposed as early as 1973 (RFC 561). Conversion from ARPANET to the Internet in the early 1980s produced the core of the current services. An email sent in the early 1970s looks quite similar to a basic text message sent on the Internet today.
Network-based email was initially exchanged on the ARPANET in extensions to the File Transfer Protocol (FTP), but is now carried by the Simple Mail Transfer Protocol (SMTP), first published as Internet standard 10 (RFC 821) in 1982. In the process of transporting email messages between systems, SMTP communicates delivery parameters using a message envelope separate from the message (header and body) itself.
USAGE
In society
There are numerous ways in which people have changed the way they communicate in the last 50 years; email is certainly one of them. Traditionally, social interaction in the local community was the basis for communication – face to face. Yet, today face-to-face meetings are no longer the primary way to communicate as one can use a landline telephone, mobile phones, fax services, or any number of the computer mediated communications such as email.
Flaming
Flaming occurs when a person sends a message with angry or antagonistic content. The term is derived from the use of the word Incendiary to describe particularly heated email discussions. Flaming is assumed to be more common today because of the ease and impersonality of email communications: confrontations in person or via telephone require direct interaction, where social norms encourage civility, whereas typing a message to another person is an indirect interaction, so civility may be forgotten.[citation needed] Flaming is generally looked down upon by Internet communities as it is considered rude and non-productive.
Email bankruptcy
Also known as "email fatigue", email bankruptcy is when a user ignores a large number of email messages after falling behind in reading and answering them. The reason for falling behind is often due to information overload and a general sense there is so much information that it is not possible to read it all. As a solution, people occasionally send a boilerplate message explaining that the email inbox is being cleared out. Harvard University law professor Lawrence Lessig is credited with coining this term, but he may only have popularized it.
In business
Email was widely accepted by the business community as the first broad electronic communication medium and was the first ‘e-revolution’ in business communication. Email is very simple to understand and like postal mail, email solves two basic problems of communication: logistics and synchronization (see below).
LAN based email is also an emerging form of usage for business. It not only allows the business user to download mail when offline, it also allows the small business user to have multiple users' email IDs with just one email connection.
Pros
The problem of logistics: Much of the business world relies upon communications between people who are not physically in the same building, area or even country; setting up and attending an in-person meeting, telephone call, or conference call can be inconvenient, time-consuming, and costly. Email provides a way to exchange information between two or more people with no set-up costs and that is generally far less expensive than physical meetings or phone calls.
The problem of synchronisation: With real time communication by meetings or phone calls, participants have to work on the same schedule, and each participant must spend the same amount of time in the meeting or call. Email allows asynchrony: each participant may control their schedule independently.
Cons
This section may contain original research. Please improve it by verifying the claims made and adding references. Statements consisting only of original research may be removed. More details may be available on the talk page. (June 2009)
Most business workers today spend from one to two hours of their working day on email: reading, ordering, sorting, ‘re-contextualizing’ fragmented information, and writing email.[64] The use of email is increasing due to increasing levels of globalisation—labour division and outsourcing amongst other things. Email can lead to some well-known problems:
Loss of context: which means that the context is lost forever; there is no way to get the text back. Information in context (as in a newspaper) is much easier and faster to understand than unedited and sometimes unrelated fragments of information. Communicating in context can only be achieved when both parties have a full understanding of the context and issue in question.
Information overload: Email is a push technology—the sender controls who receives the information. Convenient availability of mailing lists and use of "copy all" can lead to people receiving unwanted or irrelevant information of no use to them.
Inconsistency: Email can duplicate information. This can be a problem when a large team is working on documents and information while not in constant contact with the other members of their team.
Liability. Statements made in an email can be deemed legally binding and be used against a party in a court of law.
Despite these disadvantages, email has become the most widely used medium of communication within the business world. In fact, a 2010 study on workplace communication, found that 83% of U.S. knowledge workers felt that email was critical to their success and productivity at work.
Problems Attachment size limitation
Email messages may have one or more attachments. Attachments serve the purpose of delivering binary or text files of unspecified size. In principle there is no technical intrinsic restriction in the SMTP protocol limiting the size or number of attachments. In practice, however, email service providers implement various limitations on the permissible size of files or the size of an entire message.
Furthermore, due to technical reasons, often a small attachment can increase in size when sent, which can be confusing to senders when trying to assess whether they can or cannot send a file by email, and this can result in their message being rejected.
As larger and larger file sizes are being created and traded, many users are either forced to upload and download their files using an FTP server, or more popularly, use online file sharing facilities or services, usually over web-friendly HTTP, in order to send and receive them.
Information overload
A December 2007 New York Times blog post described information overload as "a $650 Billion Drag on the Economy", and the New York Times reported in April 2008 that "E-MAIL has become the bane of some people’s professional lives" due to information overload, yet "none of the current wave of high-profile Internet start-ups focused on email really eliminates the problem of email overload because none helps us prepare replies". GigaOm posted a similar article in September 2010, highlighting research that found 57% of knowledge workers were overwhelmed by the volume of email they received. Technology investors reflect similar concerns.
In October 2010, CNN published an article titled "Happy Information Overload Day" that compiled research on email overload from IT companies and productivity experts. According to Basex, the average knowledge worker receives 93 emails a day. Subsequent studies have reported higher numbers. Marsha Egan, an email productivity expert, called email technology both a blessing and a curse in the article. She stated, "Everyone just learns that they have to have it dinging and flashing and open just in case the boss e-mails," she said. "The best gift any group can give each other is to never use e-mail urgently. If you need it within three hours, pick up the phone."
Spamming and computer viruses
The usefulness of email is being threatened by four phenomena: email bombardment, spamming, phishing, and email worms.
Spamming is unsolicited commercial (or bulk) email. Because of the minuscule cost of sending email, spammers can send hundreds of millions of email messages each day over an inexpensive Internet connection. Hundreds of active spammers sending this volume of mail results in information overload for many computer users who receive voluminous unsolicited email each day.
Email worms use email as a way of replicating themselves into vulnerable computers. Although the first email worm affected UNIX computers, the problem is most common today on the more popular Microsoft Windows operating system.
The combination of spam and worm programs results in users receiving a constant drizzle of junk email, which reduces the usefulness of email as a practical tool.
A number of anti-spam techniques mitigate the impact of spam. In the United States, U.S. Congress has also passed a law, the Can Spam Act of 2003, attempting to regulate such email. Australia also has very strict spam laws restricting the sending of spam from an Australian ISP, but its impact has been minimal since most spam comes from regimes that seem reluctant to regulate the sending of spam.
The Internet is a global system of interconnected computer networks that use the standard Internet protocol suite (often called TCP/IP, although not all applications use TCP) to serve billions of users worldwide. It is a network of networks that consists of millions of private, public, academic, business, and government networks, of local to global scope, that are linked by a broad array of electronic, wireless and optical networking technologies. The Internet carries an extensive range of information resources and services, such as the inter-linked hypertext documents of the World Wide Web (WWW) and the infrastructure to support email.
Most traditional communications media including telephone, music, film, and television are reshaped or redefined by the Internet, giving birth to new services such as Voice over Internet Protocol (VoIP) and Internet Protocol Television (IPTV). Newspaper, book and other print publishing are adapting to Web site technology, or are reshaped into blogging and web feeds. The Internet has enabled or accelerated new forms of human interactions through instant messaging, Internet forums, and social networking. Online shopping has boomed both for major retail outlets and small artisans and traders. Business-to-business and financial services on the Internet affect supply chains across entire industries.
The origins of the Internet reach back to research of the 1960s, commissioned by the United States government in collaboration with private commercial interests to build robust, fault-tolerant, and distributed computer networks. The funding of a new U.S. backbone by the National Science Foundation in the 1980s, as well as private funding for other commercial backbones, led to worldwide participation in the development of new networking technologies, and the merger of many networks. The commercialization of what was by the 1990s an international network resulted in its popularization and incorporation into virtually every aspect of modern human life. As of 2011, more than 2.2 billion people – nearly a third of Earth's population — use the services of the Internet.
The Internet has no centralized governance in either technological implementation or policies for access and usage; each constituent network sets its own standards. Only the overreaching definitions of the two principal name spaces in the Internet, the Internet Protocol address space and the Domain Name System, are directed by a maintainer organization, the Internet Corporation for Assigned Names and Numbers (ICANN). The technical underpinning and standardization of the core protocols (IPv4 and IPv6) is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise.
The Internet standards describe a framework known as the Internet protocol suite. This is a model architecture that divides methods into a layered system of protocols (RFC 1122, RFC 1123). The layers correspond to the environment or scope in which their services operate. At the top is the application layer, the space for the application-specific networking methods used in software applications, e.g., a web browser program. Below this top layer, the transport layer connects applications on different hosts via the network (e.g., client–server model) with appropriate data exchange methods. Underlying these layers are the core networking technologies, consisting of two layers. The internet layer enables computers to identify and locate each other via Internet Protocol (IP) addresses, and allows them to connect to one-another via intermediate (transit) networks. Last, at the bottom of the architecture, is a software layer, the link layer, that provides connectivity between hosts on the same local network link, such as a local area network (LAN) or a dial-up connection. The model, also known as TCP/IP, is designed to be independent of the underlying hardware, which the model therefore does not concern itself with in any detail. Other models have been developed, such as the Open Systems Interconnection (OSI) model, but they are not compatible in the details of description or implementation; many similarities exist and the TCP/IP protocols are usually included in the discussion of OSI networking.
The most prominent component of the Internet model is the Internet Protocol (IP), which provides addressing systems (IP addresses) for computers on the Internet. IP enables internetworking and in essence establishes the Internet itself. IP Version 4 (IPv4) is the initial version used on the first generation of today's Internet and is still in dominant use. It was designed to address up to ~4.3 billion (109) Internet hosts. However, the explosive growth of the Internet has led to IPv4 address exhaustion, which entered its final stage in 2011,when the global address allocation pool was exhausted. A new protocol version, IPv6, was developed in the mid-1990s, which provides vastly larger addressing capabilities and more efficient routing of Internet traffic. IPv6 is currently in growing deployment around the world, since Internet address registries (RIRs) began to urge all resource managers to plan rapid adoption and conversion.
IPv6 is not interoperable with IPv4. In essence, it establishes a parallel version of the Internet not directly accessible with IPv4 software. This means software upgrades or translator facilities are necessary for networking devices that need to communicate on both networks. Most modern computer operating systems already support both versions of the Internet Protocol. Network infrastructures, however, are still lagging in this development. Aside from the complex array of physical connections that make up its infrastructure, the Internet is facilitated by bi- or multi-lateral commercial contracts (e.g., peering agreements), and by technical specifications or protocols that describe how to exchange data over the network. Indeed, the Internet is defined by its interconnections and routing policies.
Routing
Internet packet routing is accomplished among various tiers of Internet Service Providers.
Internet Service Providers connect customers (thought of at the "bottom" of the routing hierarchy) to customers of other ISPs. At the "top" of the routing hierarchy are ten or so Tier 1 networks, large telecommunication companies which exchange traffic directly "across" to all other Tier 1 networks via unpaid peering agreements. Tier 2 networks buy Internet transit from other ISP to reach at least some parties on the global Internet, though they may also engage in unpaid peering (especially for local partners of a similar size). ISPs can use a single "upstream" provider for connectivity, or use multihoming to provide protection from problems with individual links. Internet exchange points create physical connections between multiple ISPs, often hosted in buildings owned by independent third parties.
Computers and routers use routing tables to direct IP packets among locally connected machines. Tables can be constructed manually or automatically via DHCP for an individual computer or a routing protocol for routers themselves. In single-homed situations, a default route usually points "up" toward an ISP providing transit. Higher-level ISPs use the Border Gateway Protocol to sort out paths to any given range of IP addresses across the complex connections of the global Internet.[citation needed]
Academic institutions, large companies, governments, and other organizations can perform the same role as ISPs, engaging in peering and purchasing transit on behalf of their internal networks of individual computers. Research networks tend to interconnect into large subnetworks such as GEANT, GLORIAD, Internet2, and the UK's national research and education network, JANET. These in turn are built around smaller networks (see the list of academic computer network organizations).
Not all computer networks are connected to the Internet. For example, some classified United States websites are only accessible from separate secure networks.
General structure
The Internet structure and its usage characteristics have been studied extensively. It has been determined that both the Internet IP routing structure and hypertext links of the World Wide Web are examples of scale-free networks.
Many computer scientists describe the Internet as a "prime example of a large-scale, highly engineered, yet highly complex system". The Internet is heterogeneous; for instance, data transfer rates and physical characteristics of connections vary widely. The Internet exhibits "emergent phenomena" that depend on its large-scale organization. For example, data transfer rates exhibit temporal self-similarity. The principles of the routing and addressing methods for traffic in the Internet reach back to their origins in the 1960s when the eventual scale and popularity of the network could not be anticipated. Thus, the possibility of developing alternative structures is investigated. The Internet structure was found to be highly robust[33] to random failures and very vulnerable to high degree attacks.
broadband
The standards group CCITT defined "broadband service" in 1988 as requiring transmission channels capable of supporting bit rates greater than the primary rate which ranged from about 1.5 to 2 Mbit/s. The US National Information Infrastructure project during the 1990s brought the term into public policy debates.
Broadband became a marketing buzzword for telephone and cable companies to sell their more expensive higher data rate products, especially for Internet access. In the US National Broadband Plan of 2009 it was defined as "Internet access that is always on and faster than the traditional dial-up access". The same agency has defined it differently through the years.
Even though information signals generally travel nearly the speed of light in the medium no matter what the bit rate, higher rate services are often marketed as "faster" or "higher speeds". (This use of the word "speed" may or may not be appropriate, depending on context. It would be accurate, for instance, to say that a file of a given size will typically take less time to finish transferring if it is being transmitted via broadband as opposed to dial-up.) Consumers are also targeted by advertisements for peak transmission rates, while actual end-to-end rates observed in practice can be lower due to other factors.
wi-fi
To connect to a Wi-Fi LAN, a computer has to be equipped with a wireless network interface controller. The combination of computer and interface controller is called a station. All stations share a single radio frequency communication channel. Transmissions on this channel are received by all stations within range. The hardware does not signal the user that the transmission was delivered and is therefore called a best-effort delivery mechanism. A carrier wave is used to transmit the data in packets, referred to as "Ethernet frames". Each station is constantly tuned in on the radio frequency communication channel to pick up available transmissions.
Internet access
A Wi-Fi-enabled device can connect to the Internet when within range of a wireless network connected to the Internet. The coverage of one or more (interconnected) access points — called hotspots — can extend from an area as small as a few rooms to as large as many square miles. Coverage in the larger area may require a group of access points with overlapping coverage. Outdoor public Wi-Fi technology has been used successfully in wireless mesh networks in London, UK.
Wi-Fi provides service in private homes, high street chains and independent businesses, as well as in public spaces at Wi-Fi hotspots set up either free-of-charge or commercially. Organizations and businesses, such as airports, hotels, and restaurants, often provide free-use hotspots to attract customers. Enthusiasts or authorities who wish to provide services or even to promote business in selected areas sometimes provide free Wi-Fi access.
Routers that incorporate a digital subscriber line modem or a cable modem and a Wi-Fi access point, often set up in homes and other buildings, provide Internet access and internetworking to all devices connected to them, wirelessly or via cable. With the emergence of MiFi and WiBro (a portable Wi-Fi router) people can easily create their own Wi-Fi hotspots that connect to Internet via cellular networks. Now Android, Bada, iOS (iPhone), and Symbian devices can create wireless connections.[24] Wi-Fi also connects places that normally don't have network access, such as kitchens and garden sheds.
City-wide Wi-Fi
An outdoor Wi-Fi access point
In the early 2000s, many cities around the world announced plans to construct city-wide Wi-Fi networks. There are many successful examples; in 2005 Sunnyvale, California, became the first city in the United States to offer city-wide free Wi-Fi, and Minneapolis has generated $1.2 million in profit annually for its provider.
In 2004, Mysore became India's first Wi-fi-enabled city and second in the world after Jerusalem. A company called WiFiyNet has set up hotspots in Mysore, covering the complete city and a few nearby villages.
In May 2010, London, UK, Mayor Boris Johnson pledged to have London-wide Wi-Fi by 2012. Several boroughs including Westminster and Islington already have extensive outdoor Wi-Fi coverage.
Officials in South Korea's capital are moving to provide free Internet access at more than 10,000 locations around the city, including outdoor public spaces, major streets and densely populated residential areas. Seoul will grant leases to KT, LG Telecom and SK Telecom. The companies will invest $44 million in the project, which will be completed in 2015.
Campus-wide Wi-Fi
Many traditional college campuses provide at least partial wireless Wi-Fi Internet coverage. Carnegie Mellon University built the first campus-wide wireless Internet network, called Wireless Andrew at its Pittsburgh campus in 1993 before Wi-Fi branding originated.
In 2000, Drexel University in Philadelphia became the United States's first major university to offer completely wireless Internet access across its entire campus.
Direct computer-to-computer communications
Wi-Fi also allows communications directly from one computer to another without an access point intermediary. This is called ad hoc Wi-Fi transmission. This wireless ad hoc network mode has proven popular with multiplayer handheld game consoles, such as the Nintendo DS, Playstation Portable, digital cameras, and other consumer electronics devices. Some devices can also share their Internet connection using ad-hoc, becoming hotspots or "virtual routers".
Similarly, the Wi-Fi Alliance promotes a specification called Wi-Fi Direct for file transfers and media sharing through a new discovery- and security-methodology. Wi-Fi Direct launched in October 2010.
Advantages and limitations
Wi-Fi allows cheaper deployment of local area networks (LANs). Also spaces where cables cannot be run, such as outdoor areas and historical buildings, can host wireless LANs.
Manufacturers are building wireless network adapters into most laptops. The price of chipsets for Wi-Fi continues to drop, making it an economical networking option included in even more devices.
Different competitive brands of access points and client network-interfaces can inter-operate at a basic level of service. Products designated as "Wi-Fi Certified" by the Wi-Fi Alliance are backwards compatible. Unlike mobile phones, any standard Wi-Fi device will work anywhere in the world.
Wi-Fi Protected Access encryption (WPA2) is considered secure, provided a strong passphrase is used. New protocols for quality-of-service (WMM) make Wi-Fi more suitable for latency-sensitive applications (such as voice and video). Power saving mechanisms (WMM Power Save) extend battery life.
Limitations
Spectrum assignments and operational limitations are not consistent worldwide: most of Europe allows for an additional two channels beyond those permitted in the US for the 2.4 GHz band (1–13 vs. 1–11), while Japan has one more on top of that (1–14). As of 2007, Europe, is essentially homogeneous in this respect.
A Wi-Fi signal occupies five channels in the 2.4 GHz band. Any two channels numbers that differ by five or more, such as 2 and 7, do not overlap. The oft-repeated adage that channels 1, 6, and 11 are the only non-overlapping channels is, therefore, not accurate. Channels 1, 6, and 11 are the only group of three non-overlapping channels in the U.S.
Equivalent isotropically radiated power (EIRP) in the EU is limited to 20 dBm (100 mW).
The current 'fastest' norm, 802.11n, uses double the radio spectrum/bandwidth (40MHz) compared to 802.11a or 802.11g (20MHz). This means there can be only one 802.11n network on the 2.4 GHz band at a given location, without interference to/from other WLAN traffic. 802.11n can also be set to use 20MHz bandwidth only to prevent interference in dense community.
Wireless network refers to any type of computer network that is not connected by cables of any kind. It is a method by which homes, telecommunications networks and enterprise (business) installations avoid the costly process of introducing cables into a building, or as a connection between various equipment locations.[1] Wireless telecommunications networks are generally implemented and administered using a transmission system called radio waves. This implementation takes place at the physical level (layer) of the OSI model network structure.
Wireless PAN
Wireless personal area networks (WPANs) interconnect devices within a relatively small area, that is generally within a person's reach. For example, both Bluetooth radio and invisible infrared light provides a WPAN for interconnecting a headset to a laptop. ZigBee also supports WPAN applications. Wi-Fi PANs are becoming commonplace (2010) as equipment designers start to integrate Wi-Fi into a variety of consumer electronic devices. Intel "My WiFi" and Windows 7 "virtual Wi-Fi" capabilities have made Wi-Fi PANs simpler and easier to set up and configure.
Wireless LAN
A wireless local area network (WLAN) links two or more devices over a short distance using a wireless distribution method, usually providing a connection through an access point for Internet access. The use of spread-spectrum or OFDM technologies may allow users to move around within a local coverage area, and still remain connected to the network.
Products using the IEEE 802.11 WLAN standards are marketed under the Wi-Fi brand name. Fixed wireless technology implements point-to-point links between computers or networks at two distant locations, often using dedicated microwave or modulated laser light beams over line of sight paths. It is often used in cities to connect networks in two or more buildings without installing a wired link.
Wireless mesh network
A wireless mesh network is a wireless network made up of radio nodes organized in a mesh topology. Each node forwards messages on behalf of the other nodes. Mesh networks can "self heal", automatically re-routing around a node that has lost power.
Wireless MAN
Wireless metropolitan area networks are a type of wireless network that connects several wireless LANs.
WiMAX is a type of Wireless MAN and is described by the IEEE 802.16 standard.
Wireless WAN
Wireless wide area networks are wireless networks that typically cover large areas, such as between neighboring towns and cities, or city and suburb. These networks can be used to connect branch offices of business or as a public internet access system. The wireless connections between access points are usually point to point microwave links using parabolic dishes on the 2.4 GHz band, rather than omnidirectional antennas used with smaller networks. A typical system contains base station gateways, access points and wireless bridging relays. Other configurations are mesh systems where each access point acts as a relay also. When combined with renewable energy systems such as photo-voltaic solar panels or wind systems they can be stand alone systems.
Mobile devices networks
Further information: mobile telecommunications
With the development of smartphones, cellular telephone networks routinely carry data in addition to telephone conversations:
Global System for Mobile Communications (GSM): The GSM network is divided into three major systems: the switching system, the base station system, and the operation and support system. The cell phone connects to the base system station which then connects to the operation and support station; it then connects to the switching station where the call is transferred to where it needs to go. GSM is the most common standard and is used for a majority of cell phones.
Personal Communications Service (PCS): PCS is a radio band that can be used by mobile phones in North America and South Asia. Sprint happened to be the first service to set up a PCS.
D-AMPS: Digital Advanced Mobile Phone Service, an upgraded version of AMPS, is being phased out due to advancement in technology. The newer GSM networks are replacing the older system.
Uses
Some examples of usage include cellular phones which are part of everyday wireless networks, allowing easy personal communications. Another example, Inter-continental network systems, use radio satellites to communicate across the world. Emergency services such as the police utilize wireless networks to communicate effectively as well. Individuals and businesses use wireless networks to send and share data rapidly, whether it be in a small office building or across the world.
General
In a general sense, wireless networks offer a vast variety of uses by both business and home users.
"Now, the industry accepts a handful of different wireless technologies. Each wireless technology is defined by a standard that describes unique functions at both the Physical and the Data Link layers of the OSI Model. These standards differ in their specified signaling methods, geographic ranges, and frequency usages, among other things. Such differences can make certain technologies better suited to home networks and others better suited to network larger organizations."
Performance
Each standard varies in geographical range, thus making one standard more ideal than the next depending on what it is one is trying to accomplish with a wireless network. The performance of wireless networks satisfies a variety of applications such as voice and video. The use of this technology also gives room for future expansions. As wireless networking has become commonplace, sophistication increased through configuration of network hardware and software.
Space
Space is another characteristic of wireless networking. Wireless networks offer many advantages when it comes to difficult-to-wire areas trying to communicate such as across a street or river, a warehouse on the other side of the premise or buildings that are physically separated but operate as one. Wireless networks allow for users to designate a certain space which the network will be able to communicate with other devices through that network. Space is also created in homes as a result of eliminating clutters of wiring. This techonology allows for an alternative to installing physical network mediums such as TPs, coaxes, or fiber-optics, which can also be expensive.
Home
For homeowners, wireless technology is an effective option as compared to ethernet for sharing printers, scanners, and high speed internet connections. WLANs help save from the cost of installation of cable mediums, save time from physical installation, and also creates mobility for devices connected to the network. Wireless networks are simple and require one single wireless access point connected directly to the Internet via a router.
Environmental concerns
Starting around 2009, there have been increased concerns about the safety of wireless communications, despite little evidence of health risks so far. The president of Lakehead University refused to agree to installation of a wireless network citing a California Public Utilities Commission study which said that the possible risk of tumors and other diseases due to exposure to electromagnetic fields (EMFs) needs to be further investigated.
Wireless access points are also often close to humans, but the drop off in power over distance is fast, following the inverse-square law. The HPA's position is that “...radio frequency (RF) exposures from WiFi are likely to be lower than those from mobile phones.” It also saw “...no reason why schools and others should not use WiFi equipment.” In October 2007, the HPA launched a new “systematic” study into the effects of WiFi networks on behalf of the UK government, in order to calm fears that had appeared in the media in a recent period up to that time". Dr Michael Clark, of the HPA, says published research on mobile phones and masts does not add up to an indictment of WiFi.
Hahahahaha..
We meet again..huhuhuhu...
As for today entry I will talk about PROTOCOL AND CABLING.
PROTOCOL--------> can be defined as a set of rules that governs the communications between computers on a network.
COMMUNICATION PROTOCOL-----> standards that specifically address how the devices on a network communicate.
ETHERNET = Most widely used wired networks protocol. LOCAL TALK = a network protocol that was developed Macintosh computers. TOKEN RING = Involve token- passing FDDI (FIBRE DISTRIBUTED DATA INTERFACE) = A network protocol that is used primarily to
interconnect two or more local area networks, often
over large distance.
CABLE------> The medium through which information usually moves from one network device to another.
TYPE OF CABLE...
TWISTED PAIR CABLE Twisted pair cabling is a form of wiring in which two conductors (the forward and return conductors of a single circuit) are twisted together for the purposes of canceling out electromagnetic interference(EMI) from external sources. This type of cable is used for home and corporate Ethernet networks. Twisted pair cables consist of two insulated copper wires There are two types of twisted pair cables : Shielded and Unshielded
Unshielded
Shielded
OPTICAL FIBRE CABLE An 'optical fiber cable' is a cable containing one or more optical fibers. The optical fiber elements are typically individually coated with plastic layers and contained in a protective tube suitable for the environment where the cable will be deployed. It carries light impulses. It is expensive but have higher bandwidth and transmit data over longer distance.
COAXIAL CABLE
Coaxial lines confine the electromagnetic wave to the area inside the cable, between the center conductor and the shield.
The transmission of energy in the line occurs totally through the dielectric inside the cable between the conductors.
Coaxial lines can therefore be bent and twisted (subject to limits) without negative effects, and they can be strapped to conductive supports without inducing unwanted currents in them.
The most common use for coaxial cables is for television and other signals with bandwidth of multiple megahertz.
Although in most homes coaxial cables have been installed for transmission of TVsignals, new technologies (such as the ITU-TG.hn standard) open the possibility of using home coaxial cable for high-speed home networking applications (Ethernet over coax). nithin
PATCH CABLE A patch cable is an electrical or optical cable, used to connect one electronic or optical device to another for signal routing. Devices of different types (ie: a switch connected to a computer, or switch to router) are connected with patch cords, and it works. It is a very fast connection speed. Patch cords are usually produced in many different colors so as to be easily distinguishable,and are relatively short, perhaps no longer than two metres.